关于社会大数据的研究近年来不断扩大、繁荣,发展为集社会学、计算机学、物理学、心理学等多个学科于一身的交叉学科。与此同时,新的数据获得渠道、数据处理方法和工具也不断被研究者们引入社会研究领域。然而,正是因为该领域的快速兴起,社会大数据的研究方法往往未能得到足够的重视和讨论。未成形的方法规范、模糊的样本收集范围及边界等诸多问题导致类似研究难以复制,更难以像传统社会学研究方法一样可以通过实证研究结果的梳理总结得出系统的理论。本期【大数据与社会】将梳理总结关于大数据研究“陷阱”的文章,介绍大数据研究实践中所勘测到的“雷区”。
1948年11 月3 日,哈里⋅ 杜鲁门赢得美国总统选举的第二天, 芝加哥论坛报发表了新闻史上错得最荒谬的头条之一:“杜威击败杜鲁门”。这个头条来源于电话样本调查,但是却在抽样过程中由于对杜鲁门支持者采样过少而导致了错误的估计。此次事件并没有全盘否定民意调查方法本身,但是却启发调查者使用更成熟的技术、制定更严格的标准,从而使得今天的民意调查更加准确、在统计意义上更加严谨。
现在,我们停滞在一个相似的技术转折点,人类行为研究所使用的私人和社会网络数据不断。强大的计算机资源和可使用的大型社交媒体数据集结合,涌现出一个研究群体:他们使用机器学习,自然语言处理,网络分析和统计学对人口组成与人类行为进行前所未有的大规模测量。然而,越来越多的证据表明,基于大数据的预测和分析却曲解了现实社会现象。在社会大数据的研究逐渐成为“显学”的同时,社会学家需要与不同领域的学者增强方法领域的合作,从简单地使用大数据研究社会问题,过渡到优化大数据社会研究的操作、共同探讨符合学术标准并且行之有效的研究规范。
Derek Ruths 和 Jurgen Pfeffer 均来自于计算机研究领域,他们发表在《科学》(Science)杂志上的一篇《基于社交网站的大规模行为研究》(Social media for large studies of behavior)[1] 却深入探讨了社交媒体的研究通常出现的问题,并讨论了如何为大数据研究方法制定更高的标准规范
样本代表性:大数据≠全部
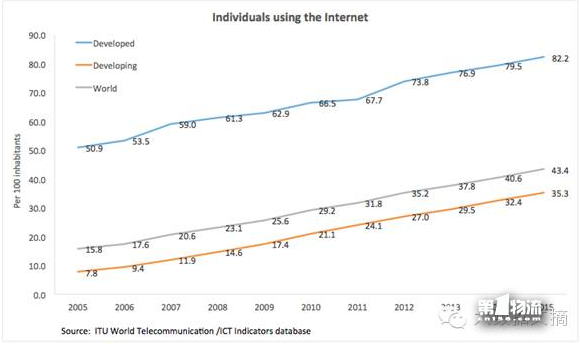
许多以大型社交媒体数据为基础的人类行为研究都潜藏着一个假设:足够大的数据样本量能排除由平台本身带来的“噪音”。然而,不同的社交媒体平台各自有大量不同的总体统计偏差。例如Instagram(译者注:大型图片分享及社交网站)对18到29岁的成年人,美国非裔,拉美裔,城市居民,特别有吸引力,而Pinterest(译者注:同样是图片分享网站)主要用户是女性,25到34岁,平均年收入10美元。两个平台用户具有不同的特征,然而,这样的样本代表性差异却从未被研究者严肃地纠正亦或是承认。此外,很多基于社交媒体的研究倾向于用社交网站的社会网络特征归纳总结人类行为。然而,发展中国家互联网使用率甚至还不足50%。用户主要以发达国家为主的社交媒体显然无法代表全世界更大范围的人类群体。根据社交网站所得出的“大数据”,其边界也需要更加审慎地界定。
图 SEQ 图 \* ARABIC 1 世界互联网使用率 (数据来源:ITU国际电信联盟是; 制图:闫蒲,Ralph Schroeder 牛津互联网研究所)蓝线代表发达国家互联网使用率,红线代表发展中国家互联网使用率。
数据“黑匣子”:被操控的数据
在《黑匣子: 操纵金钱与信息的秘密算法》(译者注:原著名为The Black Box Society: The Secret Algorithms That Control Money and Information,由哈佛大学出版社出版)一书中,作者Frank Pasquale警告公众:“(网站)可以包容、排斥、排名的权力决定了何种公众言论可以长期存在,何种会日渐式微。”
在大数据领域,网络平台同样具有操纵研究的能力和渠道。近年来,基于社交媒体数据的研究层出不穷,不少研究者都使用了网站所提供的应用数据接口(即API,Application Programming Interface)获得数据。
通过API获得社交媒体数据主要有两种渠道:搜索接口(Search API),即通过搜索一周内所发布的相关信息;另一种为即时接口(Streaming API),即通过保证接口开放接受即时信息,对于非商业伙伴的研究人员而言,网站返回的即时接口数据仅为全部数据量的1%。当研究人员日益依赖于两种API获得研究数据,并通过此类数据获得对人类网络活动、情感、组织方式认识的同时,该类数据是否具有可靠性、代表性也成为开始大量使用社交媒体数据前必须回答的问题。
Gonza?lez-Bailo?n等人在《大型社交网络抽样调查偏差评估》(Assessing the bias in samples of large online networks)这篇文章中对比了来自搜索接口和即时接口获得的不同样本,并对比不同数量的标签(hashtag,推特等社交网络媒介中出现在#符号后用来标注主题的词语)对研究结果的影响。他们抽取了两个相关信息的独立样本,样本A在英国采集,使用了搜索应用程序接口(Search API)和六个#话题标签,其中五个来自2011年的样本,一个是2012年新建的“动员”话题标签(#12M15M)。样本B1在西班牙采集,使用了即时接口(streaming API)和更广泛的70个#话题话题标签。为了更直接的对比A、B两样本,团队还从样本B中提取了一个只使用六个#话题标签的缩略版样本B2。
该研究发现通过推特应用数据接口所获得的用户社会网络结构特征很大程度上受不同接口类型以及获得样本过程中使用的标签数量影响。该研究对于使用社交媒体进行社会研究的学者有很大的启发意义:当研究者越来越依仗社交媒体平台获得研究数据时,当下流行的社会大数据取样方式很有可能导致研究结果与实际社会结构、用户行为有偏差。
Derek Ruths 和 Jurgen Pfeffer也同样提出,被全世界范围研究人员广泛只用的Twitter用户数据,并不能准确表现其用户的数据。更恶劣的情况是:社交平台管理者会通过不公开的算法操纵数据的抽样和过滤方式使得研究者无所适从。
一部分研究者因为其“嵌入式”的研究身份,建立了与社交网站平台密切的合作关系,从而获得了一般研究者无从获得的数据、算法、资源。类似的研究往往能够得出关于大规模人类行为的结论,获得一定程度的学术影响(编者注:参考上一期大数据与社会Facebook关于情绪感染的研究,http://bigdatadigest.baijia.baidu.com/article/265887 )。 然而,类似的研究往往无法复制,其研究人员对于数据来源、算法细节也往往讳莫如深。
人类行为?机器行为
很多研究者都会基于社交网站的大数据得出对人类行为和网络结构的结论,然而,类似的现象的出现很可能只是对平台设计者意图的再现,而非对人类行为的科学观测。Derek Ruths 和 Jurgen Pfeffer 认为,社交网站的设计者其实对人类行为的部分规律了然于心。譬如社交活动的同质性(“物以类聚,人以群分”),传递性(“我朋友的朋友就是我的朋友”)和邻近性(“邻近者形成一条纽带”)都被社交媒体平台的设计者们所熟知并加以运用(译者注:如Linkedin,求职类社交应用频繁地好友推荐使得用户的好友来源很大程度上来自平台的推荐而非自发的寻找)。因此,社会心理学的研究应该从平台的驱动作用剥离开来、区别对待。然而很不幸,现有的研究者并没有类似的尝试。
线上社交平台的开发者正在构建工具去服务一个特定的、实际的目的,这些尝试往往不能够代表线下的公众行为,更不能为研究者提供质量上乘的研究数据。比如,谷歌等搜索引擎会根据智能联想推测用户搜索词相关的关键词,并引导用户搜索推荐的组合(编者注:研究者会基于网站搜索数据得出对用户搜索行为的研究,及log analysis),然而基于此类数据的研究可能与用户真实的搜索意图恰好相反。这些设计往往有其合理的应用价值,但是作为研究数据,类似的设计却掩盖了人类行为的其他方面,基于此类平台的量化研究也很有可能错失对人类行为的全面体现。
此外,尽管平台设计者们致力于监管用户的规范使用,但是在所有的线上社交平台都存在大量的“僵尸号”,即大规模人为甚至机器操纵的用户账号,服务于商业与广告营销等目的。在分析社交网站大数据时,排除或纠正类似的“杂音”是极其困难的。
研究方法的桎梏
在社交大数据必须经由平台提供的现状下,研究者无法排除抽样不具代表性、噪音干扰等诸多问题。因此,在汇报关于大数据的社会行为研究结果过程中,研究者需要着重强调研究中潜在的偏差(biases)。然而,即便研究者意识到利用社交网站数据存在的偏差,相关领域的研究也往往由于研究方法本身不够严谨而存在质量问题。
代表人群(proxy population)错配:每一个社交媒体研究的问题都定义了一个兴趣人群,例如,通过社交网站研究加州地区(UC schools)大学生的投票偏好。研究者往往通过 facebook用户的个人资料设置来确定研究群体(编者注:用户可以在资料中标注自己在加州就学)。然而从真实的研究群体到社交媒体所选择的表征群体,却往往存在严重的误差。最近的一项研究表明,这种代理效应在推特的政治倾向研究中已导致错误的估计[3]。
方法和数据不具可比性:绝大多数社交媒体平台禁止研究者保存或分享他们所获取的研究数据。 因此,在传统研究领域中可以实施的数据比较在大数据研究中十分鲜见。此外,研究者也很少公开其研究方法中所使用的代码。这些都导致新方法在未经对比检验的情况下就得以发表(甚至声称比其他方法“更好”)。介于现有社交网站平台关于用户隐私可以理解的保护手段,研究人员最有可能的解决办法是尽可能增加方法和结果的比较。
多重假设检验:现有的学术氛围通常只会欢迎积极发现(positive findings) ,当多组研究都成功就某一个社会问题建模或预测时,由于无法看到负面结果,我们也无从评价哪一些积极发现是由于随机性的巧合产生,哪一些是真正具有意义的积极发现。该问题不仅仅出现大数据研究领域,解决这一问题需要研究者不仅仅报告积极结论,同时也回报负面结果,并在同一个研究中使用多个数据来源,从而得以在该研究内部计算显著性得分。
总而言之,现有的大数据研究领域在代表性、抽样方法及研究方法等多个方面都仍然具有很多问题。基于此,对大多数研究者而言,我们需要具有的是对于数据质量及偏差更细致的考察,确立更加规范的标准。因而,更准确及有效的分析将很大程度上依赖于我们对待海量数据的审慎态度。
如何减少大数据社会研究中出现的偏差